Basics of relational databases
A relational database is a collection of tables. Each table is a two-dimensional data structure organized into columns (also called fields) and rows. Columns have names and data types, and rows represent individual data entries.
Data types supported by most database systems include the INT datatype used to store integers, the REAL datatype used to store floating point real numbers, and the STRING datatype used to store text.
Operations on database tables in a relational database are performed by using a special purpose language called SQL. Further down in these notes you will find a basic introduction to SQL commands.
Getting started with sqlite
SQLite is a popular database system with good built-in support in Python. Unlike other database systems, which require a separate software installation, the SQLite system is a light weight database system that is immediately accessible via the sqlite3 python package.
Although it is possible to do everything we will want to do with SQLite purely through Python code, you may find it helpful to download and install a separate graphical GUI tool for working with SQLite databases. One good option is SQLite Studio.
Here is an example of how to create a new database in SQLite Studio. Start by selecting the Add a Database command from the Database menu. In the dialog that appears click the green plus button in the File section to make a new database file.

A new entry for this database will then appear in the Databases view on the left side of the main window. Double-click this entry to expand the view of the Example database.
Right-click on tables section of the database and select the option to make a new table.
In the table view that appears off to the right type a name for your new database. To add columns to the table, double-click in the column list area below the table name.
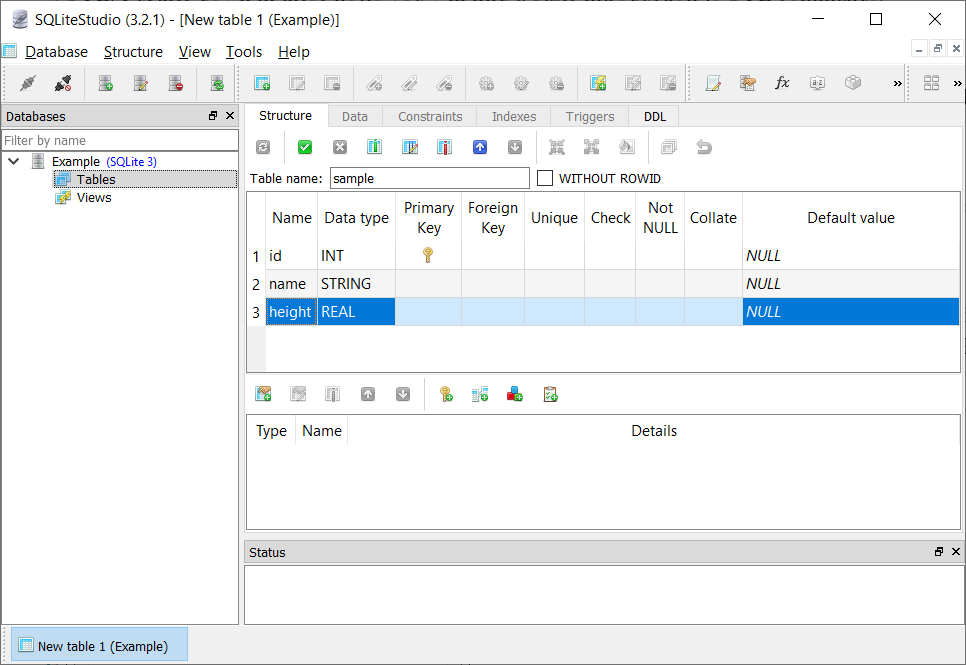
Add three columns to your sample table as shown above. To commit your changes to the database, click the green check mark button above the table name.
You can issue SQL commands to manipulate the database in the application by opening a SQL editor window. Select Open SQL editor from the tools menu to open an editor window.
Since our sample database table will start out with no data in it, the first SQL command we are going to issue is a command to insert a new row into the sample table. Paste the following code into the editor window:
INSERT INTO sample(id,name,height) VALUES(1,'Joe Gregg',1.7);
The SQL insert statement names the database table to work with followed by a list of columns to set values for.
To execute the code, click the blue run triangle.

Edit the values in the insert statement to add a couple more rows into the sample table. Be sure to give each new row a distinct id value.
You can view the current contents of the sample table by using the SQL select statement.
SELECT id, name, height FROM sample;

You can display a subset of the columns by modifying the list of columns in the select statement:
SELECT name, height FROM sample;
You can filter the results to a subset of rows by adding a WHERE clause.
SELECT id, name, height FROM sample where height > 1.0;
You can update an entry in a table by using SQL update statement:
UPDATE sample SET height = 6.1 WHERE id = 2;
Using SQL from Python
You can interact with a SQLite database from a Python program by using the sqlite3 package.
import sqlite3
The first step in working with a database is to open the database. This includes getting a connection to the database and obtaining a cursor object.
conn = sqlite3.connect('example.db')
c = conn.cursor()
print("Opened database successfully")
The sample code above assumes that the database file example.db is in the same folder as the Python program. If this is not the case, you will have to update the path to the db file accordingly.
To issue a SQL command to the database we construct a string containing the command and pass it to the cursor's execute() method.
sql = "INSERT INTO sample(id,name,height) VALUES(4,'Dobby',1.2)" c.execute(sql)
After making any changes to the contents of the database you should run the connection's commit() method to commit the changes to the database.
conn.commit()
To view the results returned by a select statement you execute the statement and then use the cursor's fetchall() method to fetch the results. This returns an iterable list of tuples containing the rows returned by the select.
sql = "SELECT name, height FROM sample WHERE height > 1.0"
c.execute(sql)
for name, height in c.fetchall():
print(name + ':' + str(height))
When you are done working with the database you should close the database connection.
conn.close()
GDP plot example
For the main example today I am going to solve the GDP plotting problem from the homework with the help of a database.
The first step is to make a new database file, GDP.db. This database will contain a single table, gdp. Here is the structure of that table.
| Column | Type | Description |
|---|---|---|
| code | STRING | Three letter country code |
| p95 | REAL | Population in 1995 |
| p05 | REAL | Population in 2005 |
| g95 | REAL | GDP in 1995 |
| g05 | REAL | GDP in 2005 |
| gpc95 | REAL | GDP per capita in 1995 |
| gpc05 | REAL | GDP per capita in 2005 |
| pg | REAL | Population growth |
| gg | REAL | Growth in GDP per capita |
The first Python file we create is a program to read data from the GDP.csv file and store it in the gdp table.
import sqlite3
import pandas as pd
# Read CSV file and isolate the columns we need
# Also do a dropna() drop any rows that are missing
data
df = pd.read_csv('GDP.csv')
df = df[['Country Code','1995','2005']].dropna()
rows = df.values
# Connect to the database
conn = sqlite3.connect('GDP.db')
c = conn.cursor()
print("Opened database successfully")
# Do an insert statement to make a row in the database for each
# row in the dataframe.
for row in rows:
c.execute("INSERT INTO gdp(code,g95,g05) VALUES (?,?,?)",row)
# Commit database changes
conn.commit()
print("Records created successfully")
conn.close()
Here is the loop that inserts new rows in the database:
for row in rows:
c.execute("INSERT INTO gdp(code,g95,g05) VALUES (?,?,?)",row)
Here rows is a numpy array containing all the data in our data frame. Each row in this array is a numpy array containing three values: a country code, gdp in 1995, and gdp in 2005.
To insert this data into the database we use an SQL insert statement. Note that the insert statement has three placeholder ? characters. The execute() method will fill those placeholders with values taken from the second parameter. Since each row in the numpy array contains the three values we need in the order they should appear in, we can use the row directly as the second parameter to execute(). Alternatively, we could have constructed a tuple that contains the required values and passed that as the second parameter.
The second program we write pulls population data from the JSON file and inserts that data into the database.
import json
import sqlite3
# Load the data into a list.
filename = 'population_data.json'
with open(filename) as f:
pop_data = json.load(f)
# Connect to the database
conn = sqlite3.connect('GDP.db')
c = conn.cursor()
print("Opened database successfully")
# Load the population data
for entry in pop_data:
if entry['Year'] == '1995':
c.execute("UPDATE gdp SET p95 = ? WHERE code = ?", (entry['Value'],entry['Country Code']))
elif entry['Year'] == '2005':
c.execute("UPDATE gdp SET p05 = ? WHERE code = ?", (entry['Value'],entry['Country Code']))
conn.commit()
# Compute gdp per capita and growth rates
c.execute("UPDATE gdp SET gpc95 = g95/p95 WHERE g95 IS NOT NULL and p95 IS NOT NULL")
c.execute("UPDATE gdp SET gpc05 = g05/p05 WHERE g05 IS NOT NULL and p05 IS NOT NULL")
c.execute("UPDATE gdp SET pg = (p05-p95)/p95 WHERE p95 IS NOT NULL and p05 IS NOT NULL")
c.execute("UPDATE gdp SET gg = (gpc05-gpc95)/gpc95 WHERE gpc95 IS NOT NULL and gpc05 IS NOT NULL")
conn.commit()
print("Records updated successfully")
conn.close()
The loop that loads the population data into the database only has to make a single pass through the data from the JSON file. In that pass we look for entries that cover the years 1995 or 2005. When we find such an entry we execute an SQL updata statement to update the appropriate row in the database. The where clause in the insert statement allows us to target the one specific row where the new data should go.
After we have inserted population data into the gdp table we are ready to compute values for the remaining columns. We can do this via a series of SQL update statements. The power of update statements is that they can update many rows at the same time. The only thing we have to be careful with is setting up an appropriate where clause in the update so the update targets only the rows where it makes sense to set a value. Missing data will show up as NULL values in the database, so we limit our updates to only those rows that do not have NULL values.
Once we have inserted all of the required data into the database, we can construct a third program that pulls data from the database to make a plot.
import sqlite3
import matplotlib.pyplot as plt
# Set up the database connection
conn = sqlite3.connect('GDP.db')
c = conn.cursor()
print("Opened database successfully")
# Run the query
sql = "SELECT pg, gg FROM gdp WHERE pg IS NOT NULL and gg IS NOT NULL"
c.execute(sql)
# Process the results
p = []
g = []
for pg, gg in c.fetchall():
if gg < 20:
p.append(pg)
g.append(gg)
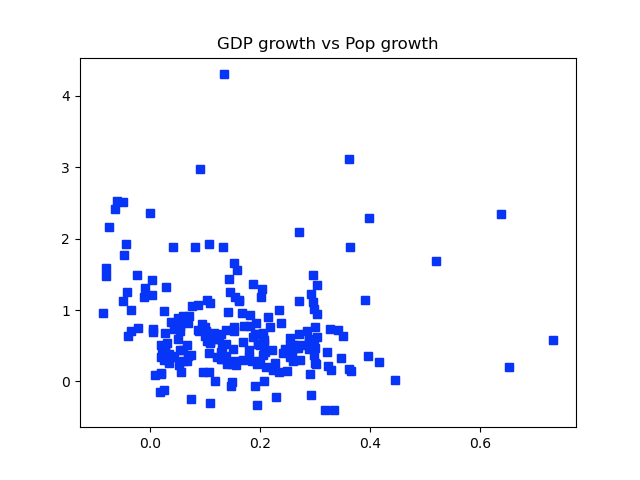
# Construct the plot
plt.plot(p,g,'bs')
plt.title('GDP growth vs Pop growth')
plt.savefig('plot.png')
print('Saved plot')
Here is the plot that results from this:
Programming assignment
The button above links to an archive containing a pair of CSV files. The file Chicago_Covid.csv contains data on Covid 19 cases and deaths from Chicago organized by zip code. The second file, Income_and_Population.csv contains data on median income and population for the same region, also organized by zip code.
Construct a database to store zip code, case counts, median income, and population. You will then write three programs:
- Write a program to read the Chicago_Covid.csv file and insert data on cases from that file into the database.
- Write a second program to read the Income_and_Population.csv file and update the data in the database with median income and population data.
- Write a third program that reads data from the database to construct a plot of median income vs. infection rates for the zip codes in the data set. The infection rate is the number of Covid 19 cases per 1000 people in the zip code. Plot the income on the x axis and the infection rate on the y axis.