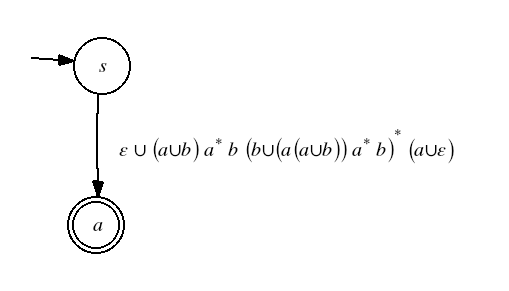Building bigger machines from smaller machines
A widely used strategy in computer science is to construct larger programs from subroutines. Most commonly, programmers write a collection of useful functions and then build up larger programs by combining those functions to solve larger problems.
We can follow a similar strategy with finite automata: we start by building very simple machines that can perform limited operations and then find ways to combine those simpler machines to make more complex machines.
A very simple machine
The simplest DFA we can construct is a DFA that decides a language consisting of a single string.
For example, the machine below decides the language L = {0110}, which is a language consisting of a single string.

Closure under set operations
A language L is a regular language if there exists a finite automaton M that decides the language.
Since a language L is a set of strings, one way to make new languages is to use standard set operations, such as union and intersection, to make new sets. An important question with each of these operations is whether the new language formed by the operation is regular if both of the original languages are regular.
In today's lecture we are going to see that for each of the standard set operations, including union, complement, and intersection the new language formed by the operation is regular if the original languages involved in the operation are regular.
Union
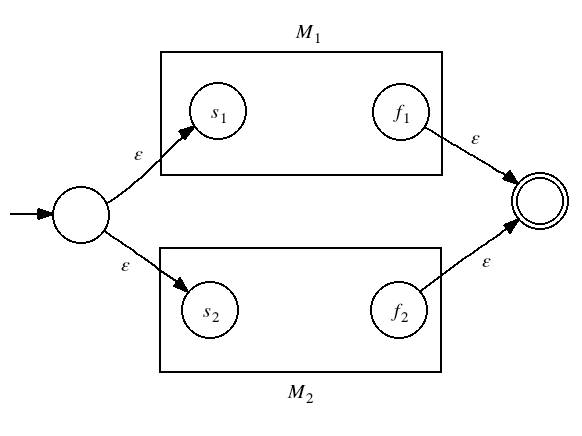
Theorem If L1 and L2 are regular languages, then the new language L = L1 ∪ L2 is regular.
Proof Since L1 is regular, there is a DFA M1 that decides the language. Since L2 is regular, there is a DFA M2 that decides the language. Here is the structure of a machine M that can decide L = L1 ∪ L2:
Complement
Theorem If L is a regular language, its complement L is also regular.
Proof If L is regular, there is a DFA M that decides L. Construct a new machine M from M by changing every non-accepting state in M to an accepting state and every accepting state in M to a non-accepting state. For any input string x ∈ L, x drives M to an accepting state. That same x will drive M to a non-accepting state. Likewise, input strings x that are no in L will drive M to a non-accepting state, which means that that same x drives M to an accepting state. Thus, M will accept x if an only if x ∈ L.
Intersection
Theorem If L1 and L2 are regular languages, then the new language L = L1 ∩ L2 is regular.
Proof By De Morgan's law, L = L1 ∩ L2 = L1 ∪ L2. By the previous two theorems this language is regular. Since L is regular, L = L is also regular.
Concatenation
If L1 and L2 are languages, then the concatenation of the two languages, L = L1 · L2, is the set of all strings of the form x1x2 where x1 ∈ L1 and x2 ∈ L2.
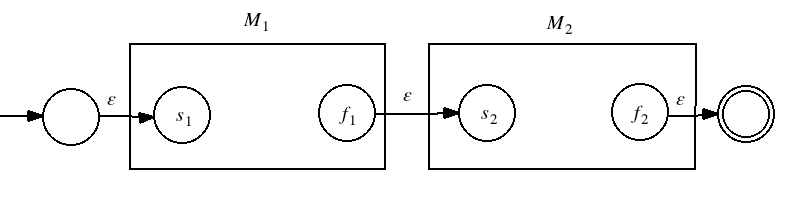
Theorem If L1 and L2 are regular languages, then the new language L = L1 · L2 is regular.
Proof Since L1 is regular, there is a DFA M1 that decides the language. Since L2 is regular, there is a DFA M2 that decides the language. Here is the structure of a machine M that can decide L = L1 · L2:
Kleene-*
If L is a language, the language L* is the language of all strings that can be written as the concatenation of 0 or more strings taken from L.
Theorem If L is a regular language, L* is also regular.
Proof If L is regular, there is a DFA M that decides L. Here is a machine that decides L*:

Regular expressions
A regular expression is an expression formed by taking strings and combining them with a set of operators:
- Concatenation: R = R1R2
- Union: R = R1 ∪ R2
- Intersection: R = R1 ∩ R2
- Kleene-*: R = R1*
- Complement: R = R1
For example, consider R = 01 ∪ 00(10)*11.
Theorem A language is regular if and only if its elements can be described by a regular expression.
Proof Let L be the set of strings generated by some regular expression R. The base elements in the regular expression are all simple strings: the sets consisting of just those strings are each regular languages, since it is easy to construct a DFA that accepts only that one string and nothing else. Since all of the regular operations that are used to combine these strings in the regular expression correspond directly to regular set operations, the combination of the base strings yields a language that is automatically regular.
To go in the opposite direction, we present an algorithm that converts any DFA into a regular expression. Let L be the language that the DFA accepts.
The algorithm consists of several steps:
- Standardize the DFA so that is has just one accepting state and no transitions that return to the start state. This may convert the DFA to an NFA: this is OK, because the subsequent steps will still work in the presence of ambiguous transitions or ε transitions.
- Repeat the following steps until only the start state and the accepting state remain:
- Select a state.
- Replace all of the transitions passing through that state with a transition that by-passes the state. This new transition will be labeled with a regular expression.
At the end of this process, we will be left with just a start state and an accepting state with just one transition between them. This transition will be labeled with a regular expression: this is the regular expression that generates L.
Example
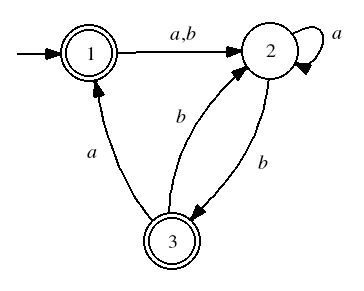
The first step is to standardize the start and final states.
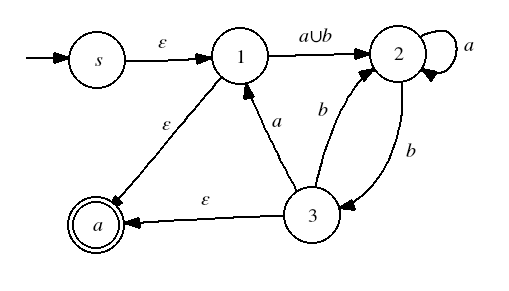
Next we eliminate state 1.
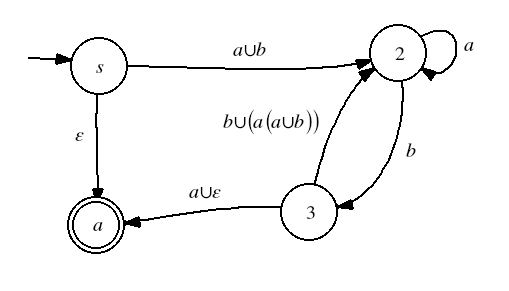
Then state 2,
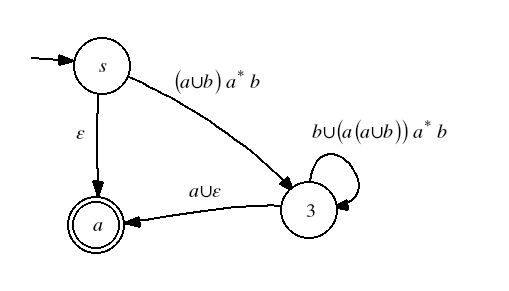
and finally state 3.